
Mistral 7B is 187x cheaper compared to GPT-4
Find how Mistral AI 7B model can be a great alternative to GPT 3.5 or 4 models with 187x cheaper in cost.


Mistral 7B is a transformer model designed for fast inference and handling longer sequences. It achieves this by utilizing grouped-query attention and sliding-window attention. Group query attention combines multi-query and multi-head attention to balance output quality and speed. Sliding-window attention extends context length by looking beyond the window size. Mistral 7B offers an 8,000-token context length, delivering low latency, high throughput, and strong performance in comparison to larger models. It also has low memory requirements at a 7B model size. This model is freely available under the permissive Apache 2.0 license without usage restrictions.
The idea here is, can we arrive at high level cost difference between Mistral AI and Chatgpt?
A new course launched for interview preparation
We have launched a new course “Interview Questions and Answers on Large Language Models (LLMs)” series.
This program is designed to bridge the job gap in the global AI industry. It includes 100+ questions and answers from top companies like FAANG and Fortune 500 & 100+ self-assessment questions.
The course offers regular updates, self-assessment questions, community support, and a comprehensive curriculum covering everything from Prompt Engineering and basics of LLM to Supervised Fine-Tuning (SFT) LLM, Deployment, Hallucination, Evaluation, and Agents etc.
Understand detailed curriculum below (Get 50% off using coupon code MED50 for first 10 users)
You can try our FREE self assessment on LLM (30 MCQs in 30 mins)
To arrive at the approximate practical cost difference between Mistral AI mistral-7b-instruct model vs ChatGPT 3.5 or 4 models, we run parallel requests to the model on the below scenarios:
We used NVIDIA A100 40GB without quantization of the model.
We ran 50 parallel requests (Note: The number of actual parallel requests depends on the machine configuration.
We ran the model for ~14.2 million input tokens and ~1.2 million output tokens
We can complete ~15.2 million tokens in under 40 minutes.
The cost of running NVIDIA A100 40GB is ~$4 per hour.
Cost calculation:
I will use the following data:
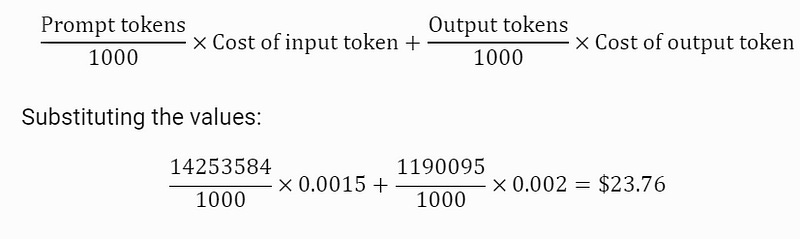
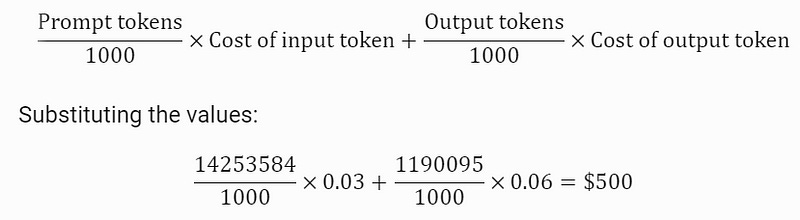
Prompt Tokens: 14,253,584
Output Tokens: 1,190,095
Cost per Input Token: $0.0015 for ChatGPT 3.5 4K model and $0.03 for ChatGPT 4 per 1K tokens
Cost per Output Token: $0.002 for ChatGPT 3.5 4K model and $0.06 for ChatGPT 4 per 1K tokens
GPT 3.5 Cost calculation:
Calculating cost for GPT 3.5
GPT 4 Cost calculation:
Calculating cost for GPT 4
Cost for Mistral AI:
The cost of running NVIDIA A100 40GB is ~$4 per hour and we can run all these tokens in under 40 minutes, so the total cost comes to $2.67
Cost comparison between Mistral AI vs ChatGPT
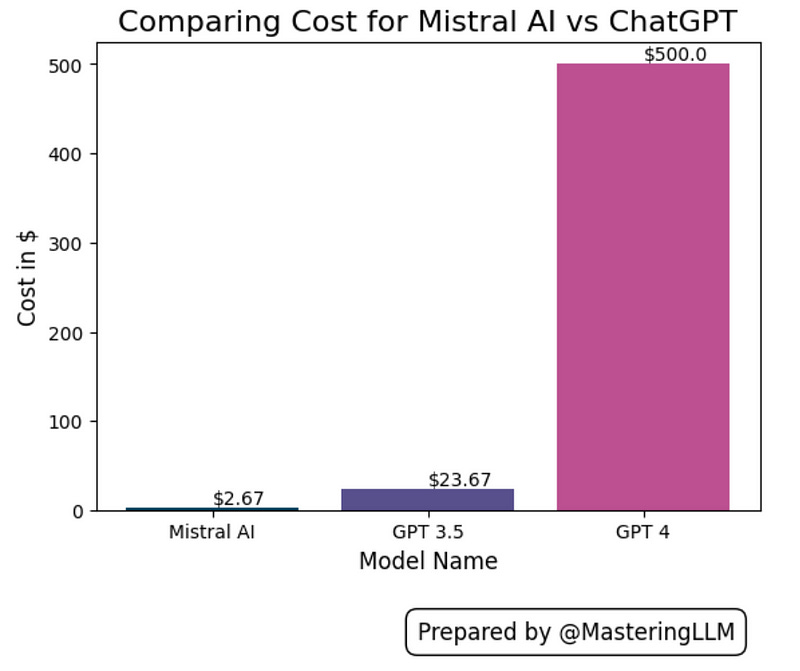
Observations:
Mistral AI is ~187x cheaper than GPT 4 and ~9x cheaper than the GPT 3.5 model.
The cost of Mistral AI can be further reduced by increasing parallel processing.
By quantizing the model, we can decrease the amount of GPU utilization, thereby enhancing efficiency.
Conclusion:
Mistral AI shows a promising alternative to the GPT 3.5 model using prompt engineering.
Mistral AI can be used where it requires high volume and faster processing time with very little cost.
Mistral AI can be used as pre-filtering to GPT 4 to reduce cost i.e. can be used to filter down search results.
Update:
There are a lot of discussions around cost comparison in the comments, here are a few points from the discussion:
The cost comparison is when you want to use a lot of tokens, for small requests on demand APIs will still be a cost-effective solution.
We found the Mistral AI model the best alternative to the re-ranking kind of model where you want to have better recall and generally utilizes high tokens (In our experiment, we found that we can increase the recall rate from ~5% to ~70% compared to open source re-ranking models)
Another use case is where we want to process a large number of news articles where getting some hit on accuracy is okay compared to the cost (Use cases like news classification, sentiment analysis, or de-duplication of news articles, etc.)
Using Mistral AI as a re-ranking model, we found using better prompt engineering techniques and better instructions, we can reduce hallucinations, and in a few cases, it’s better compared to the PaLM model.
Replicate the experiment:
Use NVIDIA A100 40GB compute instance on GCP or any other cloud service.
Use the docker instance given by Mistral AI — Quickstart | Mistral AI Large Language Models
You can use Openai specifications to use the API here Mistral AI Inference Server | Mistral AI Large Language Models
Run your code in parallel — Below is a sample code
This code will process each item in parallel using a ThreadPoolExecutor
The number of parallel processes is set to 250, but you can adjust this number as needed. The number of parallel requests depends on your machine and CPU cores.
This is a sample code and it does not save the results anywhere, so you may want to modify it to suit your needs
def check_answer(i):
try:
messages = [
{
"role": "user",
"content": "You are an assistant"
},
{
"role": "user",
"content":"""
"In the context provided in ```
- Carefully create complete summary from above definitions and context provided in ``` to provide your answer.
- Lets think step by step."
"""
},
{
"role": "user",
"content": "```context: " + context + "```"
}
]
chat_completion = openai.ChatCompletion.create(
model="mistralai/Mistral-7B-Instruct-v0.1",
messages=messages,
temperature=0,
max_tokens=4000
)
except:
return None
return chat_completion
def worker(i):
try:
result = check_answer(i)
print(f"Completed index {i}")
except concurrent.futures.TimeoutError:
print(f"check_answer({i}) timed out. Moving on to the next index.")
num_processes = 250
with concurrent.futures.ThreadPoolExecutor(max_workers=num_processes) as executor:
futures = [executor.submit(worker, i) for i in range(len(temp_result['content']))]
concurrent.futures.wait(futures)Leave your comments, share and subscribe.